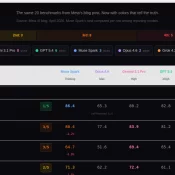
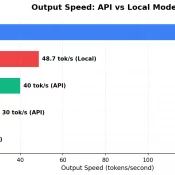
Claude Code Rate exceeded.
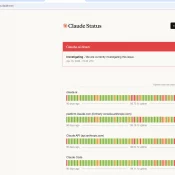
If you are getting “Rate exceeded.” when trying to re-authorize your Claude Code instance, it is probably because Anthropic’s servers are having API/login issues: Specifically, if you haven’t been heavily using Claude and you get kicked out of Claude Code with reauthorization required… for me every time it has been server issues on anthropic side and the eventually resolve. Still, that is small consolation if you are trying to finish up a project or get work done! Claude has been