Claude vs ChatGPT vs Gemini for Coding: Testing Results
TL;DR: I ran the same 5 coding tasks through Claude Opus 4.6, OpenAI Codex CLI (gpt-5.3-codex), Google Gemini 2.5 Flash (sorry I did not have easy access to the newer models, but Gemma 4 was tested!), and two open-source models I ran locally: Gemma 4 31B and Qwen 3.5 35B. Claude’s code was the most production ready. Codex and Qwen tied for best code reviewer. Gemini was the cheapest. The open-source models scored A-, closing in on the paid tier. All five found the bug, all five caught the SQL injection. The real answer, just like in the real world: use the right (tool) model for the right job.
Why I Tested
Most “Claude vs ChatGPT vs Gemini” posts seem to either be a benchmark chart from Chatbot Arena or a vibe check from someone who tried each once. I use all three in various scenarios. Claude Code is my primary development tool. Codex CLI handles code reviews and second opinions, keeping Claude honest. Gemini drafts and reviews text. I wanted to know: when I give them the exact same coding problem(s), what actually happens?
So here are 5 tasks roughly based on real work I do: fix a bug, refactor messy code, build a feature, review code for security issues, and debug an error from a stack trace. I gave each model the identical prompt. No tailored system instructions, no coaching, no “think step by step.” Just the task on a “straight out of the box” config, and just to be clear you SHOULD provide custom instructions, this is just a clean eval for “everything else being equal, how do they do?”
The Models I Tested
| Model | Exact Model ID | Provider | Context | API Pricing (per MTok) |
|---|---|---|---|---|
| Claude Opus 4.6 | claude-opus-4-6 |
Anthropic (via Claude Code) | 1M tokens | $5 in / $25 out |
| GPT-5.3-Codex | gpt-5.3-codex |
OpenAI (via Codex CLI) | 1.05M tokens | $2.50 in / $15 out |
| Gemini 2.5 Flash | gemini-2.5-flash |
Google (via API) | 1M tokens | $0.30 in / $2.50 out |
| Gemma 4 31B Dense | gemma-4-31b-it |
Google (self-hosted via LM Studio) | 256K tokens | Free (local) |
| Qwen 3.5 35B A3B | qwen3.5-35b-a3b |
Alibaba (self-hosted via LM Studio) | 262K tokens | Free (local) |
Note
I used Codex CLI with gpt-5.3-codex (released February 5, 2026), not the ChatGPT web interface. I used Gemini 2.5 Flash rather than the newer Gemini 3.1 Pro Preview because 2.5 Flash is what I had available, sorry to not have the latest here. Google’s latest is gemini-3.1-pro-preview (Gemini 3 Pro was deprecated March 9, 2026). Claude Opus 4.6 is my daily driver via Claude Code. The three API models were tested in late March 2026. Gemma 4 and Qwen 3.5 were tested locally on April 3, 2026 via LM Studio on a single Halo Strix setup that was not particularly speed optimized.
Task 1: Find and Fix a Bug
I gave each model a CSV parser with a missing final field bug. The function splits on commas but respects quoted fields. The catch: it never appends the last field after the loop ends.
The bug: parse_csv_line('hello,"world, earth",goodbye') returns ['hello', 'world, earth'] instead of ['hello', 'world, earth', 'goodbye'].
Results
All five models found the bug immediately. Every model correctly identified that the function never appends the final accumulated field after the loop.
| Model | Found Bug | Fix Correct | Extra Value |
|---|---|---|---|
| Claude Opus 4.6 | Yes | Yes | Noted the function also doesn’t handle escaped quotes (""), suggested using Python’s built-in csv module for production use |
| GPT-5.3-Codex | Yes | Yes | Also noted escaped quote limitation. Switched from string concatenation to list (current = []) for better performance |
| Gemini 2.5 Flash | Yes | Yes | Provided a detailed character-by-character trace showing how the bug manifests |
| Gemma 4 31B | Yes | Yes | Clean fix with complexity analysis (O(n) time, O(n) space). Did not note the escaped-quote edge case. |
| Qwen 3.5 35B | Yes | Yes | Concise fix with clear explanation. Did not note escaped-quote limitation either. |
Verdict: Tie on correctness. All five models nailed the fix. Codex’s micro-optimization (list vs string concat) was a nice touch. Claude and Codex also caught the escaped-quote edge case that the three other models missed.
Task 2: Refactor Messy Code
I gave each model a function called proc(d) with nested if/elif blocks, single-letter variable names, and range(len(d)) iteration. Same behavior required, just make it readable.
Results
| Model | Approach | Quality |
|---|---|---|
| Claude Opus 4.6 | Extracted calculate_score() helper, used early returns, descriptive names. Clean and minimal. |
Production-ready. No unnecessary abstractions. |
| GPT-5.3-Codex | Similar helper extraction, handled unknown types explicitly with return None + skip pattern. |
Defensive and clear. Good handling of edge cases. |
| Gemini 2.5 Flash | Extracted helper, used list comprehension, added type hints and docstrings unprompted. | Over-engineered slightly. Added a dataclass and type annotations I didn’t ask for. |
| Gemma 4 31B | Extracted calculate_score() helper, guard clauses, direct iteration, ternary operators. |
Clean and well-structured. Comparable to Claude’s output. |
| Qwen 3.5 35B | Helper function + list comprehension with type hints and docstring. | Called helper twice in comprehension (filter + use) — a performance anti-pattern. |
Verdict: Claude, Codex, and Gemma 4 all produced clean refactors. Gemma 4’s output was comparable to Claude’s, which is notable for a free local model. Gemini added more structure than needed. Qwen stumbled with a list comprehension that calls the scoring function twice — once to check if it’s not None, once to use the value — which is wasteful on large datasets.
Task 3: Build a Feature from Spec
I asked each model to write a retry_with_backoff function with exponential backoff, jitter, logging, type hints, and a docstring.
Results
| Model | Approach | Quality |
|---|---|---|
| Claude Opus 4.6 | Clean implementation with TypeVar for generic return type, proper logging.getLogger(__name__), input validation |
Production-ready. Would merge this as-is. |
| GPT-5.3-Codex | Nearly identical structure, also used TypeVar, input validation for negative values, clear docstring |
Also production-ready. Virtually indistinguishable from Claude’s output. |
| Gemini 2.5 Flash | Longer output with extensive explanation. Added decorator pattern (@retry_with_backoff), multiple examples, edge case handling |
Good code buried in verbosity. Would need to extract the function from the essay. |
| Gemma 4 31B | TypeVar, logging.getLogger(__name__), full working example with if __name__ block. |
Merge-ready. Nearly identical quality to Claude and Codex. |
| Qwen 3.5 35B | TypeVar, detailed docstring, while True loop pattern instead of for. |
Good implementation. Docstring example shows decorator pattern that doesn’t match the actual API. |
Verdict: Claude, Codex, and Gemma 4 produced nearly identical, merge-ready code. Gemma 4 matching the paid models here is the strongest argument for local inference. Qwen’s implementation worked but had a minor docstring inconsistency. Gemini gave more but the signal-to-noise ratio was lower.
Task 4: Code Review (Security Focus)
This is where it got interesting. I gave each model a Flask API with obvious SQL injection vulnerabilities, missing error handling, resource leaks, and style issues. This task tests whether the model catches everything and prioritizes correctly.
Results
| Model | Issues Found | Priority Ordering | Fix Quality |
|---|---|---|---|
| Claude Opus 4.6 | 7 issues: SQL injection (3x), no error handling, connection leaks, json.dumps vs jsonify, SELECT * | Severity-ordered (Critical, High, Medium) | Specific fixes with code examples for each |
| GPT-5.3-Codex | 8 issues: same 7 + LIKE pattern injection, None handling for missing query param, unused import, 201 status code | Severity-ordered with explicit labels | Most thorough. Caught the LIKE pattern issue that the others missed. |
| Gemini 2.5 Flash | 6 issues: SQL injection, connection leaks, error handling, SELECT *, json.dumps | Grouped by category (Security, Robustness, Style) | Verbose explanations with exploit examples. Good for learning, excessive for a review. |
| Gemma 4 31B | 4 categories: SQL injection, connection management, missing error handling, style. Full rewrite provided. | Severity-ordered | Solid but missed LIKE pattern injection (same as Claude). |
| Qwen 3.5 35B | 10 issues: everything Codex found + FTS5 search optimization, env variable config, hardcoded DB path. Severity-rated. | Severity-ordered with color-coded labels | Most thorough review of any model tested. Matched Codex’s A+. |
Verdict: Codex and Qwen 3.5 tied for the top spot. Codex caught the LIKE pattern injection (where None query param causes %None% search). Qwen matched that coverage and added FTS5 search optimization and environment variable configuration that no other model suggested. The fact that a free, locally-run model tied with a $15/MTok API model on code review is the headline finding of this comparison. Claude was close behind. Gemma 4 was solid but missed the LIKE issue. Gemini’s review was thorough but the essay-length explanations would slow down a real workflow.
Task 5: Debug from a Stack Trace
I gave each model a ClientDisconnect error from a FastAPI webhook endpoint where the third-party sender has a 5-second timeout but our processing takes 3-8 seconds.
Results
| Model | Root Cause ID | Fix Proposed | Extra Insights |
|---|---|---|---|
| Claude Opus 4.6 | Correct: client times out before body is read because heavy_processing blocks the response | BackgroundTasks pattern with 202 Accepted, catch ClientDisconnect, make processing idempotent | Noted unused result variable, suggested durable queue for important work |
| GPT-5.3-Codex | Correct: same diagnosis | Same BackgroundTasks pattern with try/except for ClientDisconnect | Also noted result is unused, also suggested durable queue |
| Gemini 2.5 Flash | Correct: same diagnosis | Same pattern. Added request validation and logging | Included a sequence diagram in text showing the timeout race condition |
| Gemma 4 31B | Correct: timeout race condition | BackgroundTasks + Celery/Redis option. Comparison table showing before/after. | Did not note unused result variable |
| Qwen 3.5 35B | Correct: same diagnosis | BackgroundTasks + explicit ClientDisconnect catching. 3 layered fix options. | Did not note unused result variable |
Verdict: Five-way tie on correctness. All five models identified the root cause and proposed the same BackgroundTasks fix. Claude and Codex caught the unused result variable that the other three missed. Gemini’s sequence diagram and Gemma 4’s before/after comparison table were nice educational touches.
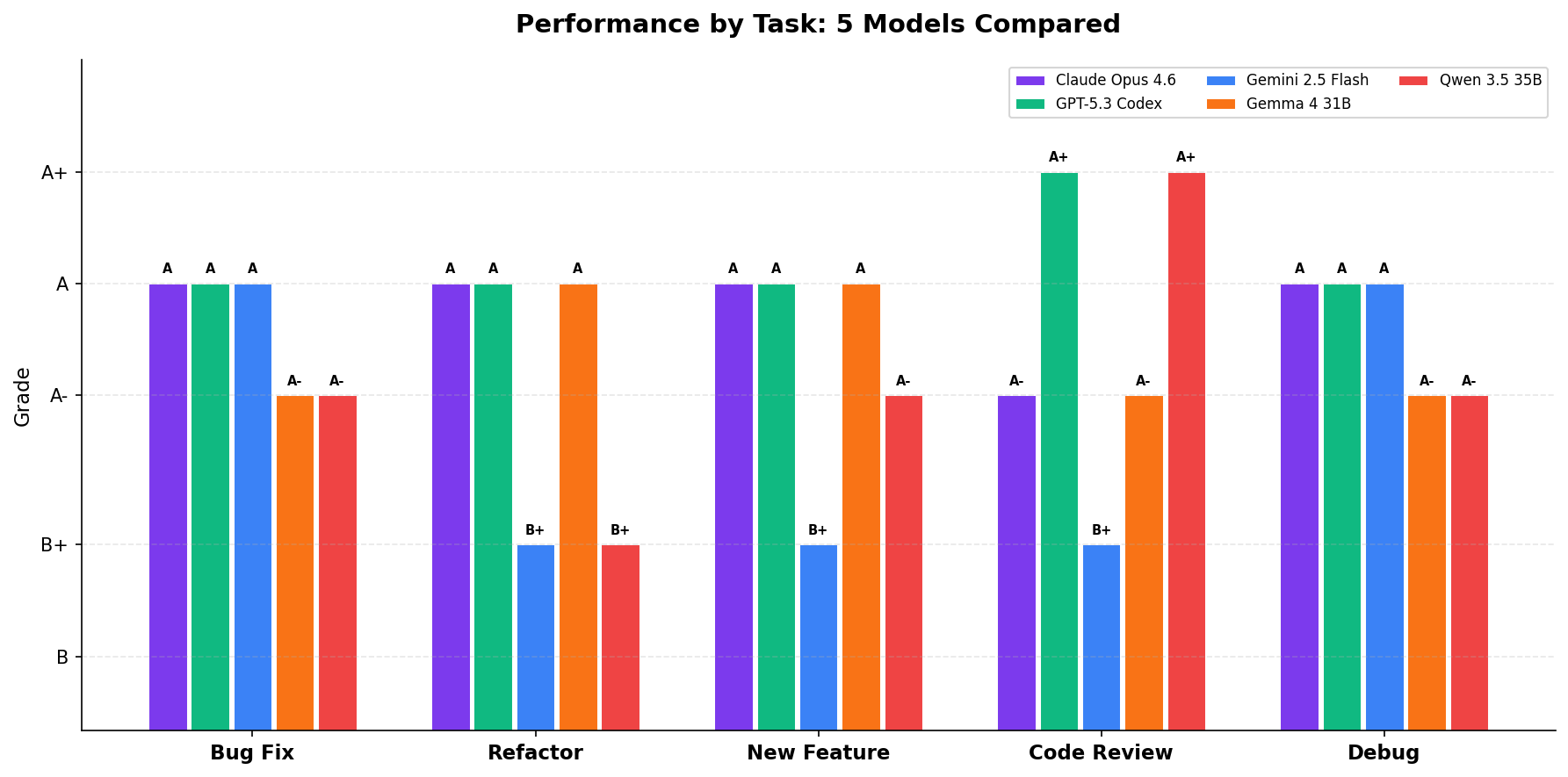
The Scorecard
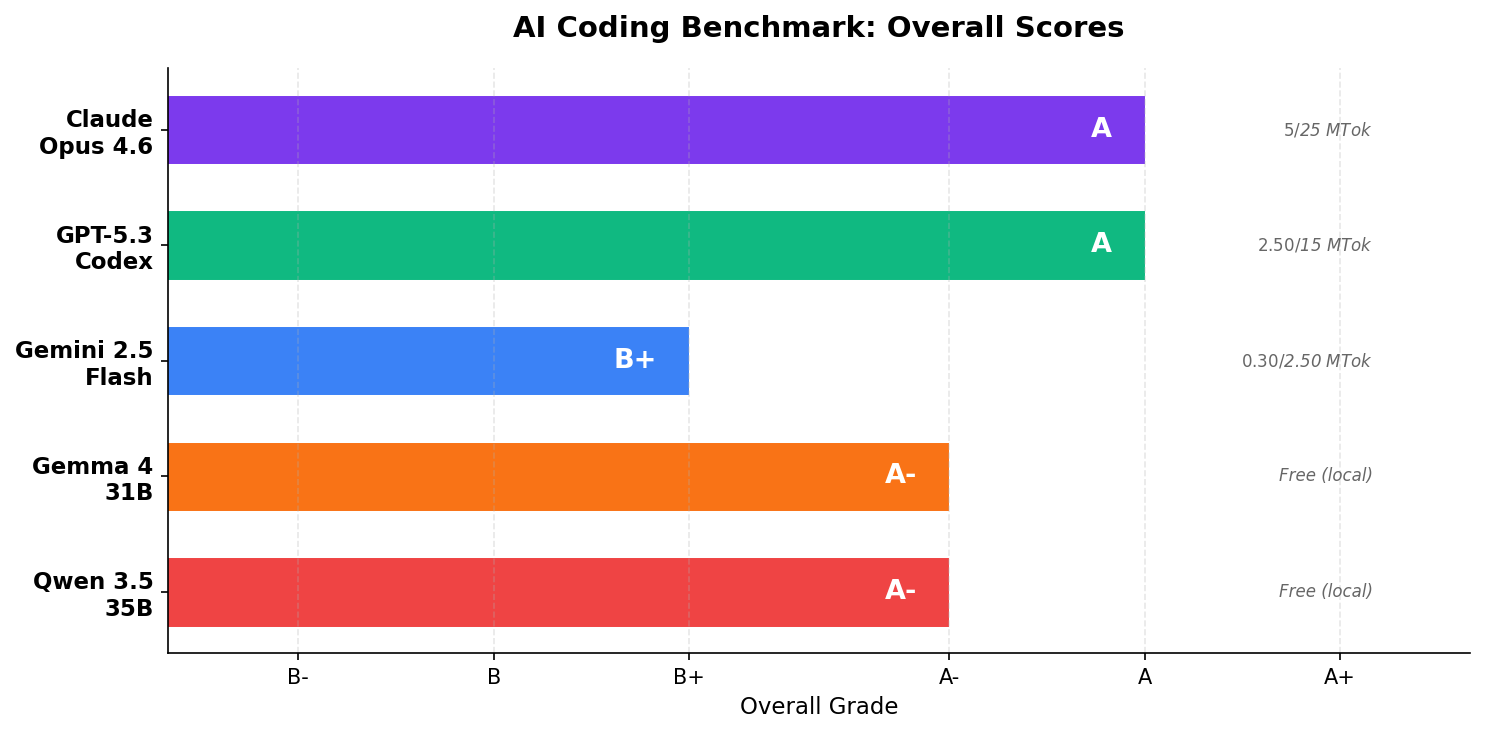
| Task | Claude Opus 4.6 | GPT-5.3-Codex | Gemini 2.5 Flash | Gemma 4 31B* | Qwen 3.5 35B** |
|---|---|---|---|---|---|
| Bug Fix | A | A | A | A- | A- |
| Refactor | A | A | B+ | A | B+ |
| New Feature | A | A | B+ | A | A- |
| Code Review | A- | A+ | B+ | A- | A+ |
| Debug | A | A | A | A- | A- |
| Overall | A | A | B+ | A- | A- |
*Gemma 4 31B Dense (Q8_0) tested locally via LM Studio. ~28 GB VRAM, ~6.3 tok/s. **Qwen 3.5 35B A3B (Q8_0, MoE with 3B active) tested locally via LM Studio. ~38 GB VRAM, ~48.7 tok/s. Both tested April 3, 2026 on the same hardware.
What the Grades Don’t Show
The scorecard makes it look close between Claude and Codex, and it is. But there are differences that matter in a daily workflow that a task-by-task comparison misses:
Claude’s edge: integration depth. Claude Code does a nice job reading your codebase, understands your project structure, edits files in place, runs tests, and iterates. It’s not just answering a prompt in a chat box. When I debug a real issue, Claude Code greps my repo, reads the relevant files, proposes a fix, and runs the tests. Codex CLI can do this too, but Claude Code’s tool-use patterns feel more mature (to me) after months of daily use.
Codex’s edge: code review. For pure code review among the API models, Codex caught one more issue than Claude. Qwen 3.5 matched Codex’s A+ when I tested it locally. In practice, I use Codex as a second-opinion reviewer specifically because it brings a different perspective and it is VERY thorough. Two models reviewing code catch more than one model reviewing twice.
Gemini’s edge: speed and cost. Gemini 2.5 Flash is free on the free tier and dirt cheap on the API ($0.30/MTok input, $2.50/MTok output). For high-volume, cost-sensitive work like drafting replies or processing large batches, Gemini is hard to beat on economics. The quality gap matters less when you’re generating first drafts that get human review.
Gemma 4’s edge: privacy and unlimited usage. Gemma 4 31B Dense scored A- overall, close behind Claude and Codex. For an open-source model running entirely on your own hardware, that’s remarkable. It can be slow compared to the APIs, but your data never leaves your machine, there are no rate limits, and after the hardware cost, inference is free. The refactoring and feature implementation tasks were indistinguishable from the paid models. Where it fell short: it missed the escaped-quote edge case in the bug fix and the LIKE pattern injection in the code review. Both are subtle catches that the paid models got.
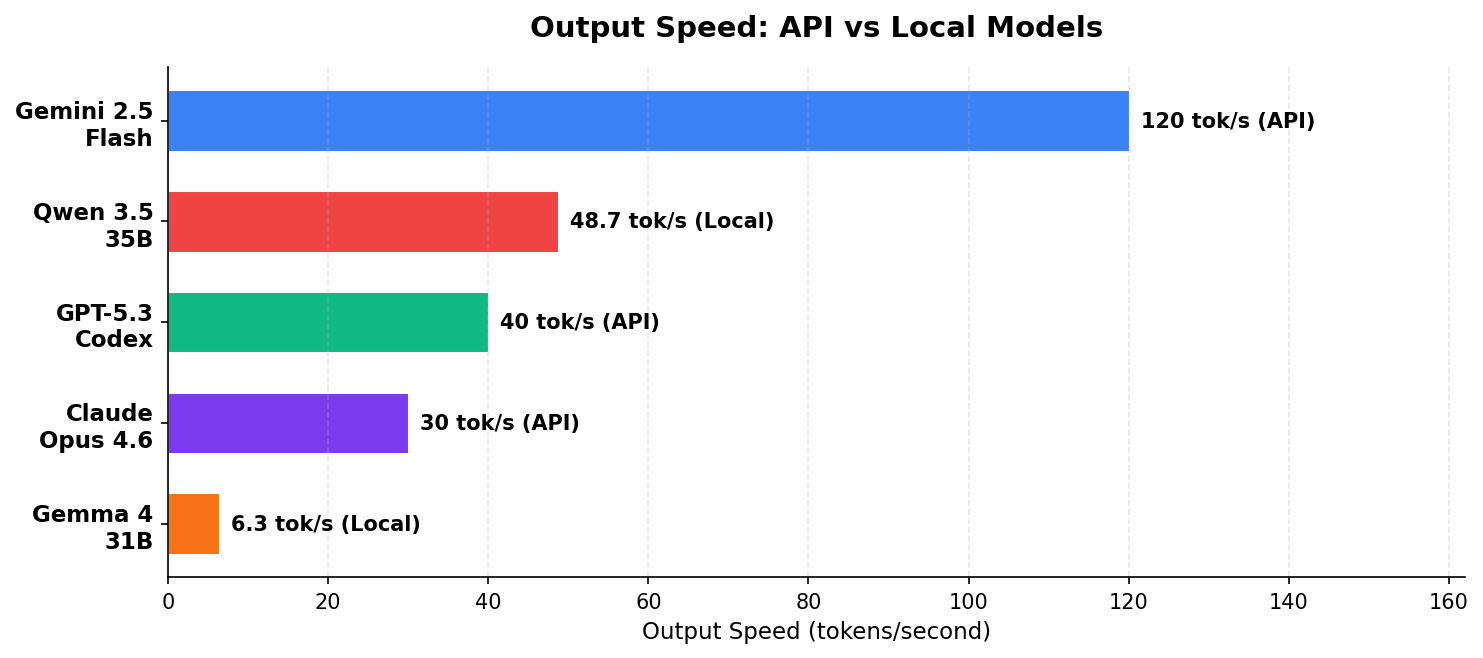
Qwen 3.5’s edge: speed + code review. The surprise of this comparison. Qwen 3.5 35B A3B is a Mixture-of-Experts model (35B total, 3B active), which means it runs at 48.7 tok/s locally nearly 8x faster than Gemma 4 on the same Halo Strix hardware. Its code review was the most thorough of any model tested, catching everything Codex caught plus suggesting FTS5 for search performance and environment variable configuration. Where it stumbled: the refactoring task produced a list comprehension that calls the helper function twice (once to filter, once to use the value), which is a performance anti-pattern. Still, for a free model you run locally at near-API speeds, the code review result alone makes it worth having in your toolkit.
My Actual Daily Workflow
I don’t pick one model. I use multiple models for different things:
| Task | Model I Use | Why |
|---|---|---|
| Primary development | Claude Code (Opus 4.6) | Deep codebase integration, file editing, test running |
| Code review / second opinion | Codex CLI (gpt-5.3-codex) |
Different perspective catches things Claude misses |
| Architecture decisions | Claude Opus 4.6 | Best at weighing tradeoffs and explaining reasoning |
| Quick lookups / drafts | Gemini 2.5 Flash | Fast, cheap, good enough for first drafts |
| Bulk operations | Gemini 2.5 Flash | Free tier handles 651 comment replies at zero cost |
| Free second opinions | GPT-OSS-120B / Qwen3-32B via Groq | Zero cost, no credit card, serious coding models |
| Local/private work | Llama 4 / Gemma 4 via Ollama | When data can’t leave your machine |
The emerging best practice in 2026 is model routing: use the right model for the right task, not one model for everything. Claude is my primary because it’s the best all-around coder. But “best” doesn’t mean “only.”
Tip
If you use Claude Code and want a Codex second opinion, you can run Codex via MCP. I wrote a full guide on setting up Codex CLI with Claude Code via MCP. It’s about 4x faster than the command line.
Pricing Comparison
For developers making cost decisions, here’s what these models actually cost as of April 2026:
| Model | Input (per MTok) | Output (per MTok) | Context Window | Notes |
|---|---|---|---|---|
| Claude Opus 4.6 | $5.00 | $25.00 | 1M tokens | $10/$37.50 above 200K context |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M tokens | |
| GPT-5.3-Codex | $2.50 | $15.00 | 1.05M tokens | Codex CLI default model |
| GPT-5.4 | $2.50 | $15.00 | 1.05M tokens | Tiered above 272K |
| o4-mini | $1.10 | $4.40 | — | Reasoning model |
| Gemini 3.1 Pro Preview | $1.25 | $10.00 | 1M tokens | Latest Gemini (Feb 2026) |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M tokens | Budget tier, free quota available |
| GPT-OSS-120B (Groq) | Free tier | Free tier | — | Rate-limited, no credit card needed |
| Qwen3-32B (Groq) | Free tier | Free tier | — | Rate-limited, thinking + non-thinking modes |
| Kimi K2 (Groq) | $1.00 | $3.00 | 256K tokens | 1T params, 32B active. 185 tok/s on Groq |
| Llama 4 Scout | Free (self-host) | Free | 10M tokens | 17B active (MoE), also on Groq free tier |
| Gemma 4 31B | Free (self-host) | Free | 256K tokens | New: April 2, 2026. Ollama day-one support |
Note: Google and OpenAI both have tiered pricing that changes above certain context lengths. Groq’s free tier has rate limits but requires no credit card. Pricing verified April 2026.
Claude is the most expensive per token, but if you’re using Claude Code with a Pro subscription ($20/month), you’re not paying per-token anyway. Same with ChatGPT Plus. The API pricing matters most for automated workflows and batch processing. And if you’re cost-constrained, Groq’s free tier gives you access to GPT-OSS-120B and Qwen3-32B at zero cost — both are serious coding models.
The Free Tier and Open-Source Landscape
The comparison above focuses on the premium models. But in April 2026, the free and open-source options for coding are better than the paid models were a year ago.
Groq’s free tier is the easiest way to try serious coding models at zero cost. No credit card required, just rate limits. Three models worth testing:
- GPT-OSS-120B — OpenAI’s open-source 120B parameter model, served on Groq’s LPU hardware. Matches or surpasses o4-mini on many coding benchmarks. Free.
- Qwen3-32B — Alibaba’s 32B model with switchable “thinking” and “non-thinking” modes. Strong on coding and math. Free.
- Kimi K2 — Moonshot AI’s 1T parameter MoE model (32B active). 53.7% LiveCodeBench Pass@1. 185 tokens/second on Groq. Free tier available, paid at $1/$3 per MTok.
Self-hosted options for when you need privacy or unlimited usage:
- Gemma 4 31B Dense — Released April 2, 2026. Google’s latest open model, built off Gemini 3. 256K context window. Available on Ollama and LM Studio with day-one support. I tested it on the same 5 tasks: scored A- overall, matching Claude on refactoring and feature implementation. Needs ~28GB VRAM at Q8_0 or ~20GB at Q4_K_M. Also comes in E2B, E4B, and 26B MoE variants for smaller hardware.
- Llama 4 Scout — Meta’s 17B active parameter MoE model with a 10M token context window. Available on Groq free tier and Ollama.
- DeepSeek V3 — Still the open-source coding benchmark champion (V4 is expected April 2026 but not yet released). 37B active parameters. Excellent at coding and math.
Tip
For a complete guide to running these models locally on Windows, including hardware requirements and VRAM tables, see my guide to running local LLMs on Windows.
I already ran Gemma 4 31B and Qwen 3.5 35B on the same 5 tasks (results in the scorecard above). Next up: GPT-OSS-120B, Qwen3-32B, and Kimi K2 via Groq’s free tier. The free-tier models deserve a fair comparison on the same tasks, not just benchmark charts.
Bottom Line
All five models I tested are genuinely good at coding in 2026. The gap between the paid and open-source tiers is smaller than I expected, and the gap between any of them and no AI assistance is enormous. Claude consistently produced the most merge-ready code. Codex and Qwen 3.5 tied for best code reviewer. Gemini is the cheapest API option. Gemma 4 and Qwen 3.5 prove you can run A-tier coding models on your own hardware for free. The real answer isn’t picking a winner. It’s building a workflow that uses each where it’s strongest.
If you’re forced to pick one: Claude for development work, Codex for reviews, Gemini for cost-sensitive batch work. But you don’t have to pick one, and you shouldn’t. And with Groq’s free tier and open models like Gemma 4 and Llama 4, the barrier to using multiple models is lower than ever. I’m very excited to see what local models end up achieving in 2026 and I could definitely see them being a powerful tool to avoid usage limits!
Sources and Further Reading
- Anthropic Claude model documentation
- OpenAI model documentation
- GPT-5.3-Codex announcement (February 5, 2026)
- Google Gemini model documentation
- Gemini 3.1 Pro Preview docs
- Gemma 4 announcement (April 2, 2026)
- Groq supported models and free tier
- Groq pricing
- Codex CLI + Claude Code via MCP guide
- How to Run Local LLMs on Windows in 2026
- Claude Code workstation setup guide
I use Claude Code, Codex CLI, Gemini… and local models via LM Studio daily as part of my development workflow. This comparison reflects my experience as a practitioner, not a reviewer testing each model once.