Meta Muse Spark: The Honest Scorecard (3 Wins Out of 20)
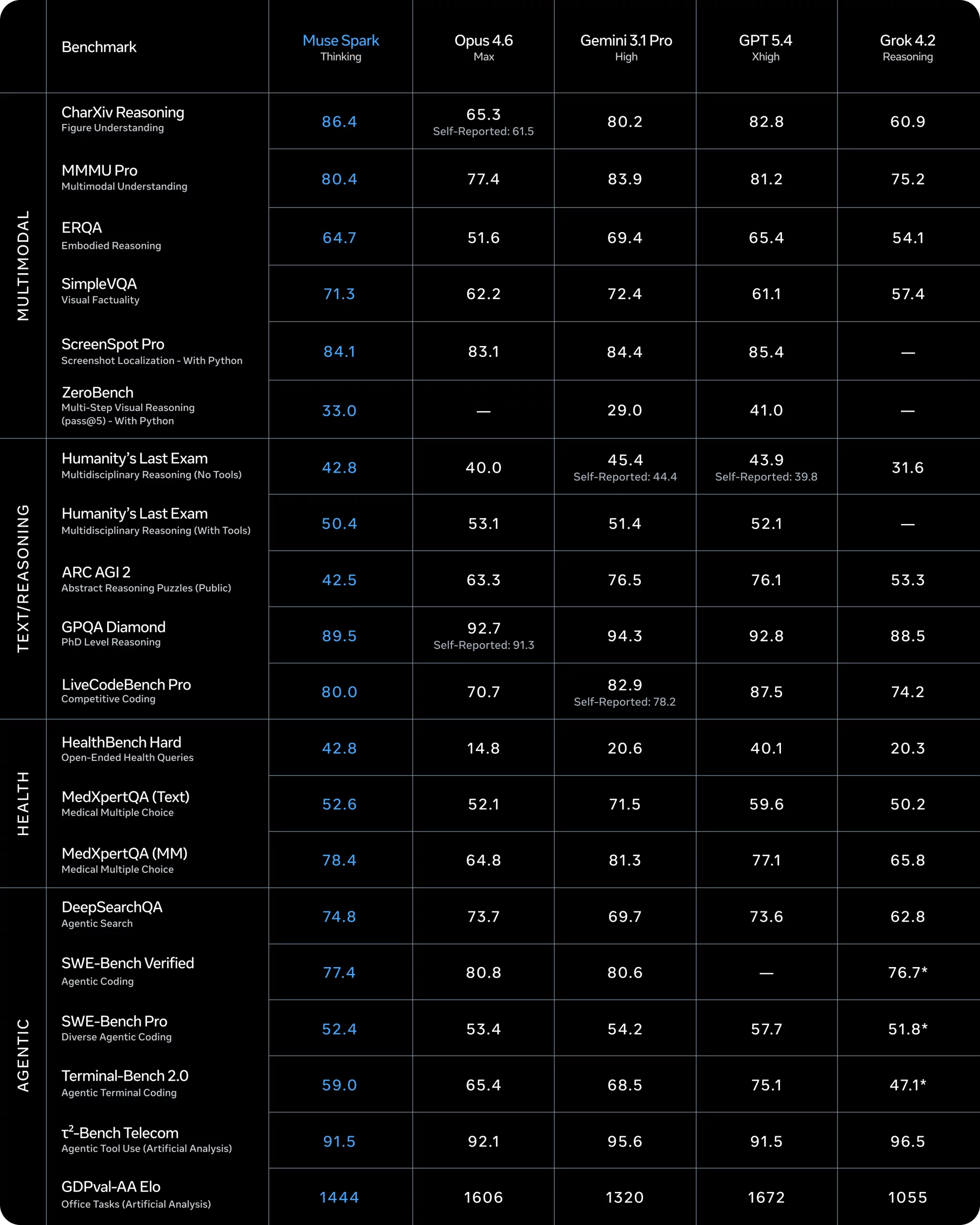
Meta just released Muse Spark, the first model from their new Superintelligence Labs. Along with it came a 20-benchmark comparison chart. The chart highlights every Muse Spark score in blue, which makes it look like Muse is leading across the board.
The original Meta release table/graphic just highlighted their column and it made it seem almost as if they won every row… They did not win every test (far from it) so maybe the the table could use some actual color coding.
Same data, same 20 benchmarks, same five models. Just with colors that reflect who actually leads each row. Sorry the formatting still isn’t as nice as I would like but 🤷♂️
The first column tells what place Muse was for each test, then each test % is broken down individually in the remaining columns:
The same 20 benchmarks from Meta’s blog post. Now with colors that tell the truth.
Source: Meta AI blog, April 2026. Muse Spark’s rank computed per row among reporting models.
| Benchmark | Rank |
Muse Spark
Thinking
|
Opus 4.6
Max
|
Gemini 3.1 Pro
High
|
GPT 5.4
Xhigh
|
Grok 4.2
Reasoning
|
|---|---|---|---|---|---|---|
| Multimodal | ||||||
|
CharXiv Reasoning
Figure Understanding
|
1/5 | 86.4 | 65.3 Self-Reported: 61.5 |
80.2 | 82.8 | 60.9 |
|
MMMU Pro
Multimodal Understanding
|
3/5 | 80.4 -4.2% |
77.4 | 83.9 | 81.2 | 75.2 |
|
ERQA
Embodied Reasoning
|
3/5 | 64.7 -6.8% |
51.6 | 69.4 | 65.4 | 54.1 |
|
SimpleVQA
Visual Factuality
|
2/5 | 71.3 -1.5% |
62.2 | 72.4 | 61.1 | 57.4 |
|
ScreenSpot Pro
Screenshot Localization (w/ Python)
|
3/4 | 84.1 -1.5% |
83.1 | 84.4 | 85.4 | — |
|
ZeroBench
Multi-Step Visual Reasoning (pass@5, w/ Python)
|
2/3 | 33.0 -19.5% |
— | 29.0 | 41.0 | — |
| Text / Reasoning | ||||||
|
Humanity’s Last Exam
Multidisciplinary Reasoning (No Tools)
|
3/5 | 42.8 -5.7% |
40.0 | 45.4 Self-Reported: 44.4 |
43.9 Self-Reported: 39.8 |
31.6 |
|
Humanity’s Last Exam
Multidisciplinary Reasoning (With Tools)
|
4/4 | 50.4 -5.1% |
53.1 | 51.4 | 52.1 | — |
|
ARC AGI 2
Abstract Reasoning Puzzles (Public)
|
5/5 | 42.5 -44.4% |
63.3 | 76.5 | 76.1 | 53.3 |
|
GPQA Diamond
PhD-Level Reasoning
|
4/5 | 89.5 -5.1% |
92.7 Self-Reported: 91.3 |
94.3 | 92.8 | 88.5 |
|
LiveCodeBench Pro
Competitive Coding
|
3/5 | 80.0 -8.6% |
70.7 | 82.9 Self-Reported: 78.2 |
87.5 | 74.2 |
| Health | ||||||
|
HealthBench Hard
Open-Ended Health Queries
|
1/5 | 42.8 | 14.8 | 20.6 | 40.1 | 20.3 |
|
MedXpertQA (Text)
Medical Multiple Choice
|
3/5 | 52.6 -26.4% |
52.1 | 71.5 | 59.6 | 50.2 |
|
MedXpertQA (MM)
Medical Multiple Choice (Multimodal)
|
2/5 | 78.4 -3.6% |
64.8 | 81.3 | 77.1 | 65.8 |
| Agentic | ||||||
|
DeepSearchQA
Agentic Search
|
1/5 | 74.8 | 73.7 | 69.7 | 73.6 | 62.8 |
|
SWE-Bench Verified
Agentic Coding
|
3/4 | 77.4 -4.2% |
80.8 | 80.6 | — | 76.7 * |
|
SWE-Bench Pro
Diverse Agentic Coding
|
4/5 | 52.4 -9.2% |
53.4 | 54.2 | 57.7 | 51.8 * |
|
Terminal-Bench 2.0
Agentic Terminal Coding
|
4/5 | 59.0 -21.4% |
65.4 | 68.5 | 75.1 | 47.1 * |
|
τ²-Bench Telecom
Agentic Tool Use (Artificial Analysis)
|
4/5 | 91.5 -5.2% |
92.1 | 95.6 | 91.5 | 96.5 |
|
GDPval-AA Elo
Office Tasks (Artificial Analysis)
|
3/5 | 1444 -13.6% |
1606 | 1320 | 1672 | 1055 |
Data from Meta AI’s Muse Spark announcement. Visualization by jdhodges.com.
Where Muse Spark Wins
Muse Spark takes first place on 3 of 20 benchmarks. These are legitimate strengths, not noise:
- CharXiv Reasoning (86.4): Clear lead in figure understanding. 3.6 points ahead of GPT 5.4.
- HealthBench Hard (42.8): Strongest on open-ended health queries. Nearly 3 points ahead of GPT 5.4, and more than double Opus and Gemini.
- DeepSearchQA (74.8): Narrow win in agentic search, just 1.1 points ahead of Opus 4.6.
Where Muse Spark Struggles
The gaps at the bottom of the table are harder to explain away:
- ARC AGI 2 (42.5): Dead last. 34 points behind Gemini’s 76.5. This is not a close race.
- Terminal-Bench 2.0 (59.0): 16 points behind GPT 5.4’s 75.1 on agentic terminal coding.
- MedXpertQA Text (52.6): 19 points behind Gemini’s 71.5 on medical multiple choice.
- HLE With Tools (50.4): Last among the four models that reported scores.
The Takeaway
Muse Spark is a competitive model. It has real strengths in health, multimodal reasoning, and agentic search. But the original chart’s uniform blue highlighting makes it look like Muse leads everywhere, and it does not. Gemini 3.1 Pro leads on 8 of 20 rows. GPT 5.4 leads on 6. Muse Spark leads on 3.
This is not a knock on the model itself. It is a knock on the presentation. When you color-code the actual results, the story changes.
This analysis uses only the scores from Meta’s own published comparison chart. Rankings are computed per row among models that reported scores for that benchmark. This is not an independent benchmark rerun. Where Meta noted discrepancies between their evaluation and a model maker’s self-reported score, both numbers are shown.
If you found this useful, share it. If you have questions or spot an error, leave a comment below.